行业洞察 |雷军年度演讲,王壮人形机器人AI技术发布
魔法数据
2022-08-14 20:06 北京

打开网易新闻查看精彩图片
昨晚的朋友圈被雷军的年度演讲刷屏了。雷军讲述了自己人生中多次经历的挫折和迷茫,分享了他从人生低谷中走过的心得体会,让每一个在创业路上的人都能感同身受。
就在演讲结束前,雷军扔出了一颗王者炸弹——全尺寸仿生人形机器人CyberOne。小编发现在功能介绍中提到了CyberOne的听觉传感器结合音频算法可以识别6大类45种人类情感语音,外加85种环境声识别。
而这包括混杂语言的识别,比如:“我的iPad不能下载APP在线朗读英语在线朗读英语,你能不能陪我去Apple Store修一下”在线朗读英语,“明天是dealine,我的论文还没准备好然而”,“老板的行程需要调整,请查收邮箱”...
这种混杂着英文的中文在我们的日常交流中经常出现。除了英语,其他小语种也出现在中文句子中。的重要挑战之一。对于人机交互语音识别系统,Code-switch带来的挑战主要体现在以下三个方面。

打开网易新闻查看精彩图片
1、重度非母语口音
其他语言混入中文不是我们的母语,我们的发音会有各种方言口音。比如闽南的普通话和天津的普通话,口音不同,更不用说人们说的非母语了。汉语有八种方言,即:普通话、吴语、湘语、赣语、客家话、闽南语、闽南语和粤语。其中,普通话是最接近标准普通话的方言,其他方言在声学发音和语言表现上都与标准普通话有显着差异。由于大多数普通话使用者掌握普通话作为第二语言,他们的普通话发音不可避免地受到他们母语发音的强烈影响。一些数据显示,大约80%的普通话使用者有不同程度的方言口音。当说话者具有某种方言口音时在线朗读英语,为标准普通话构建的语音识别器的性能往往会显着下降。

2、不同的语言有不同的音素
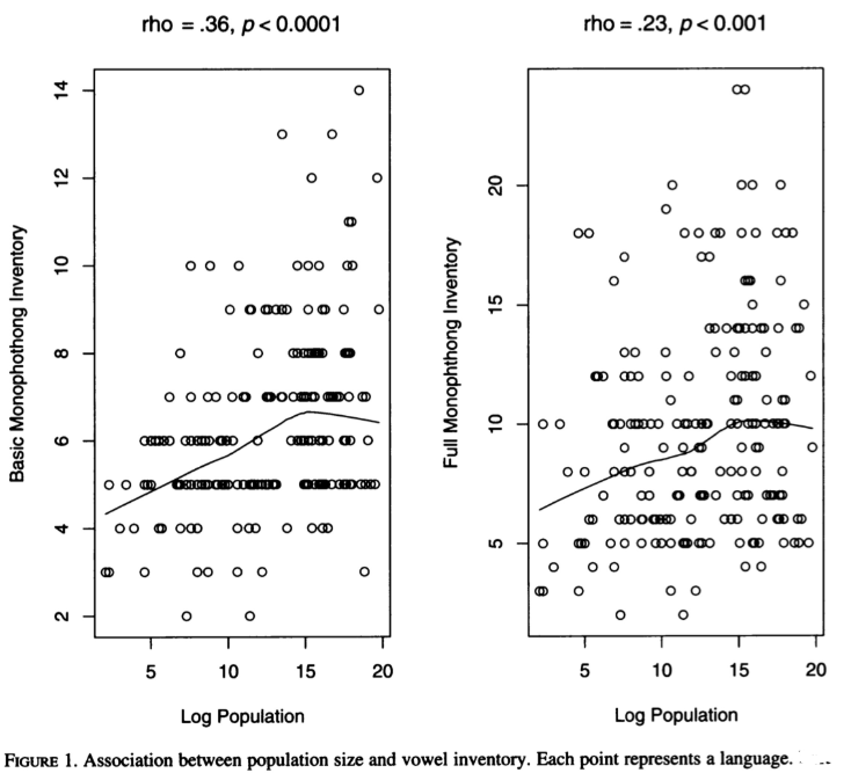
Hay和Bauer在《Linguistics Student's Handbook》(2007))中研究了说话人的数量和一些语言的类型信息,包括音素的数量,当然实验结果如下。横坐标代表人口(Logarithmic population, Log Population),纵坐标代表元音的个数,每个小圆圈代表一种语言。左图是基本元音的情况,右图是额外元音的情况.
打开网易新闻查看精彩图片
以上研究认为,音素的数量与人口有关,从而导致多语种之间的音素差异。在语音识别中,声学模型通常处理人类语言的原始音频波形,预测每个波形的相应音素,通常在字符或子词级别。语言模型指导声学模型,丢弃在正确语法和讨论主题的约束下不可能的预测。由于Code-switch包含多种语言,音素构成不同行业洞察 |雷军年度演讲,王壮人形机器人AI技术发布,这会增加混合声学模型的建模难度。
3、带注释的混合语言语料库很少
以上两个问题都是技术问题。 Code-switch 语音识别面临的基本挑战是带注释的混合语言语料库的稀缺性。由于此类数据的录制需要双语甚至多语种的人,录制成本较高,耗时较长,因此混杂语言的语音语料库非常稀缺。秦彦民的《Data Augmentation for end-to-end Code-Switching Speech Recognition》等论文使用TTS数据增强方案来提升Code-switch语音识别系统的性能。

打开网易新闻查看精彩图片

打开网易新闻查看精彩图片
对于Code-switch语音识别所面临的挑战,解决问题的本质还是数据。假设有足够多的 Code-switch 语音识别数据,通过让神经网络从大量数据中学习相关的口音、多样的音素信息等 Code-switch 引起的问题,Code-switch 语音识别系统自然会更加健壮。 . 对于记录多语种混合数据,专业的数据公司可以帮助算法工程师节省大量的人力、物力、财力。目前,麦格数据(北京爱数智慧科技有限公司)拥有多场景多语言的相关语料数据。示例如下:
中英混合音频数据集:
口音英语读取音频数据集:
 外教口语一对一学习多久能出效果?这些因素你必须知道
外教口语一对一学习多久能出效果?这些因素你必须知道 一个月口语拿7分?从这三方面分享超实用备考心得
一个月口语拿7分?从这三方面分享超实用备考心得 北京丰台区托福培训机构学费
北京丰台区托福培训机构学费 温州雅思价格查询
温州雅思价格查询














热门信息
阅读 (2506)
1 张雪峰直言:这三个大学专业“失宠”,就业率低,报考需谨慎阅读 (2489)
2 适合高中英语学习的25部英文电影,太好看了,你看过几部?阅读 (2175)
3 old man不是“老人”的意思,下次别翻译错了阅读 (2159)
4 全国**英语能力测试(NEPTP)申请指南【文末有福利】阅读 (1412)
5 潜心研究促成长,躬行教学见成效——记新世纪高中英语组